Product Spotlight
Drop any messy CSV/Excel file into a watched folder and get back a clean, analytics-ready version, powered by a rules engine plus an AI brain that I designed and built end-to-end.
I built Data Agentic AI as a plug-and-play Data-Quality Agent that can sit in front of any data pipeline—NGOs, public health, finance, HR, research, or private healthcare. It watches folders, profiles files, finds issues, and can fix them automatically using a combination of safe rules and carefully-guarded AI.
Links for more details:


Data Agentic AI Universal Data-Quality Agent
Corrupted Files
Data Agent
Fixed Files
------------------------
-----------------------------------
--------------------------------
Problem My Agent Solves:
Every organization I’ve worked with wrestles with the same spreadsheets:
-
Missing values in key fields
-
Wrong or inconsistent dates
-
Duplicate rows that quietly double-count people
-
Broken emails, phone numbers, and links
These issues quietly damage KPIs, dashboards, funding reports, and leadership decisions, and fixing them by hand wastes hours of staff time.

What the Data Agent Does:
Think of it as a “washing machine” for data.
-
Drop – A user drops any CSV/Excel file into a watched folder (rules or rules_ai).
-
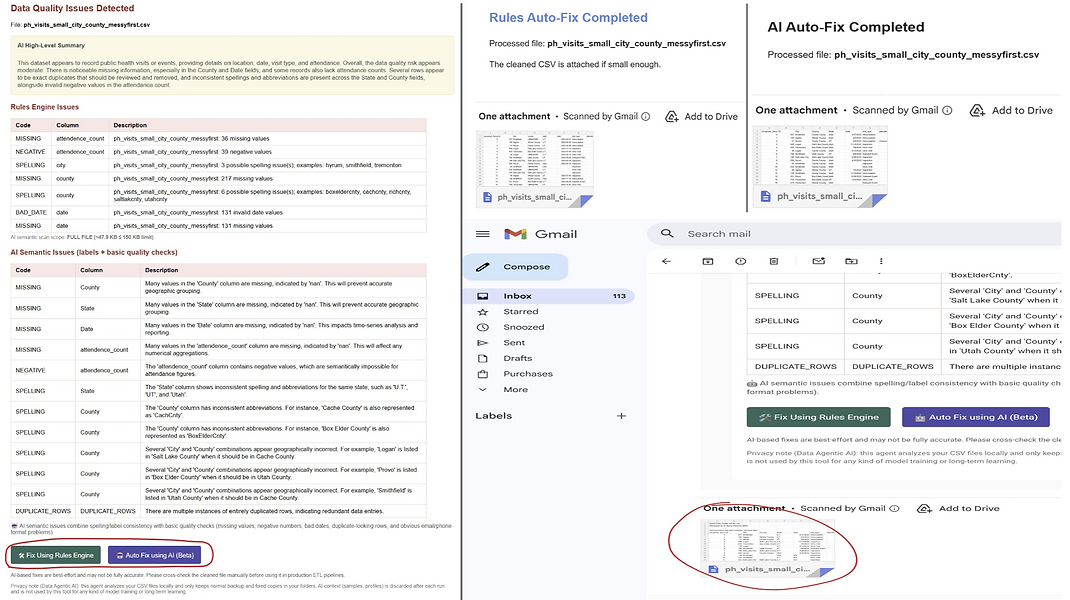
Detect – The agent scans for missing values, negatives, bad dates, invalid emails/phones/URLs, duplicates, and label/spelling issues.
-
Report – It logs issues into a MySQL table and sends a clear HTML email summarizing what it found.
-
Fix (three options):
-
One-click Rules Auto-Fix – deterministic clean-up via SQL fix functions.
-
One-click AI Auto-Fix (G mode) – a guarded AI path that cleans the file end-to-end for smaller files, then dedupes again.
-
Manual Fix Mode – staff edit the file themselves while the agent keeps re-checking until all non-spelling issues are resolved.
Data Agent Operational Doc
-
-
Result – The agent saves a Final Clean CSV: duplicates removed, dates standardized, obvious errors fixed, and ready for dashboards or ETL pipelines.
Rules + AI, With Guardrails:
I designed the architecture so that safety comes first and AI is added only when it’s clearly requested.
-
Rules-only by default – Any standard folder (like uploads or rules) uses only deterministic rule-based fixes, which is ideal for sensitive data.
-
Dedicated AI folder (rules_ai) – Only files dropped here are eligible for GPT/Gemini clean-up, so teams always know when AI is in the loop.
-
File-size gate (e.g., 150 KB) – If a file is bigger than the configured limit, the agent automatically falls back to the Rules pipeline to keep costs and latency under control.
-
Respect for personal data – The AI prompt is explicitly instructed never to invent new emails, phone numbers, or URLs, and to only apply small, local fixes (like trimming spaces or removing @@).
This combination means teams get the power of AI when they want it, with the reliability of a traditional rules engine underneath.


Built for Multiple Departments:
Because the rules and architecture are generic, the same agent works across many domains:
-
NGOs & Social Programs – Clean youth attendance, volunteer logs, and donor/export files before reporting to funders.
-
Public Health Departments – Standardize clinic data, normalize county/city names, and validate date fields before they hit surveillance or KPI dashboards.
-
Hospitals & Clinics – Clean EHR exports before loading to data warehouses like BigQuery or Redshift.
-
Finance, HR, and CRM Teams – Validate invoices, employee rosters, and customer lists so downstream systems receive trusted data.
Multi-Department Adoption:
Because of its flexibility and my previous NGO work, an organization like Code for Good has taken this Data Agent into their environment as a reusable data-quality layer—demonstrating that the same tool can be used across different departments and sectors with minimal changes.

Developer-Friendly & Extensible:
I didn’t stop at a black-box tool; I built a clean developer surface so engineers can add new rules in minutes.
“Add a new rule in 3 steps” pattern:
-
Detect in profiling.py – log a new issue code when a condition is met.
-
Fix in fix_engine.py – write a SQL-based fixer and register it in the FIXERS map.
-
(Optional) Teach AI – update the AI system prompt so GPT/Gemini also understands and respects the new rule.
This makes the agent a framework, not just a one-off script—teams can keep extending it as their data matures.
Low-Code / No-Code Version (n8n & ETL):
To make the system accessible beyond Python developers, I also mapped the entire agent into n8n, a drag-and-drop automation platform: file triggers, spreadsheet nodes, OpenAI nodes, and email nodes recreate the same behavior visually.
The same concept can plug into:
-
Apache NiFi
-
AWS Glue / Lambda / Step Functions
-
Airflow and other ETL tools
as a standard “data-quality checkpoint” before data flows into warehouses and dashboards.

From an Employer’s perspective:
This project highlights my ability to:
-
Architect and implement a full data-quality platform (Python, MySQL, AI APIs, email, and safety layer).
-
Balance innovation and governance by mixing deterministic rules with controlled AI.
-
Design for non-technical users (one-click email buttons, friendly emojis, and clear status messages).
-
Think beyond a single project and build something that NGOs, public health departments, and private companies can all reuse.
For data engineering, data quality, or AI-driven automation, this agent is a live example of how I approach complex problems: end-to-end, safe, and practical.